Visual Question Answering
Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks
- intro: Facebook AI Research
- arxiv: http://arxiv.org/abs/1502.05698v1
- github: https://github.com/facebook/bAbI-tasks
VQA: Visual Question Answering
- intro: ICCV 2015
- arxiv: http://arxiv.org/abs/1505.00468
- homepage: http://visualqa.org/
Ask Your Neurons: A Neural-based Approach to Answering Questions about Images
- intro: ICCV 2015
- arxiv: http://arxiv.org/abs/1505.01121
- project: https://www.mpi-inf.mpg.de/departments/computer-vision-and-multimodal-computing/research/vision-and-language/visual-turing-challenge/
- video: https://www.youtube.com/watch?v=QZEwDcN8ehs&hd=1
Exploring Models and Data for Image Question Answering
- arxiv: http://arxiv.org/abs/1505.02074
- gtihub(Tensorflow): https://github.com/paarthneekhara/neural-vqa-tensorflow
- github(Python+Keras): https://github.com/ayushoriginal/NeuralNetwork-ImageQA
Are You Talking to a Machine? Dataset and Methods for Multilingual Image Question Answering
Teaching Machines to Read and Comprehend
- intro: Google DeepMind
- arxiv: http://arxiv.org/abs/1506.03340
- github: https://github.com/deepmind/rc-data
- github(Theano/Blocks): https://github.com/thomasmesnard/DeepMind-Teaching-Machines-to-Read-and-Comprehend
- github(Tensorflow): https://github.com/carpedm20/attentive-reader-tensorflow
Neural Module Networks
- intro: CVPR 2016
- arxiv: http://arxiv.org/abs/1511.02799
- github: https://github.com/jacobandreas/nmn2
Image Question Answering using Convolutional Neural Network with Dynamic Parameter Prediction
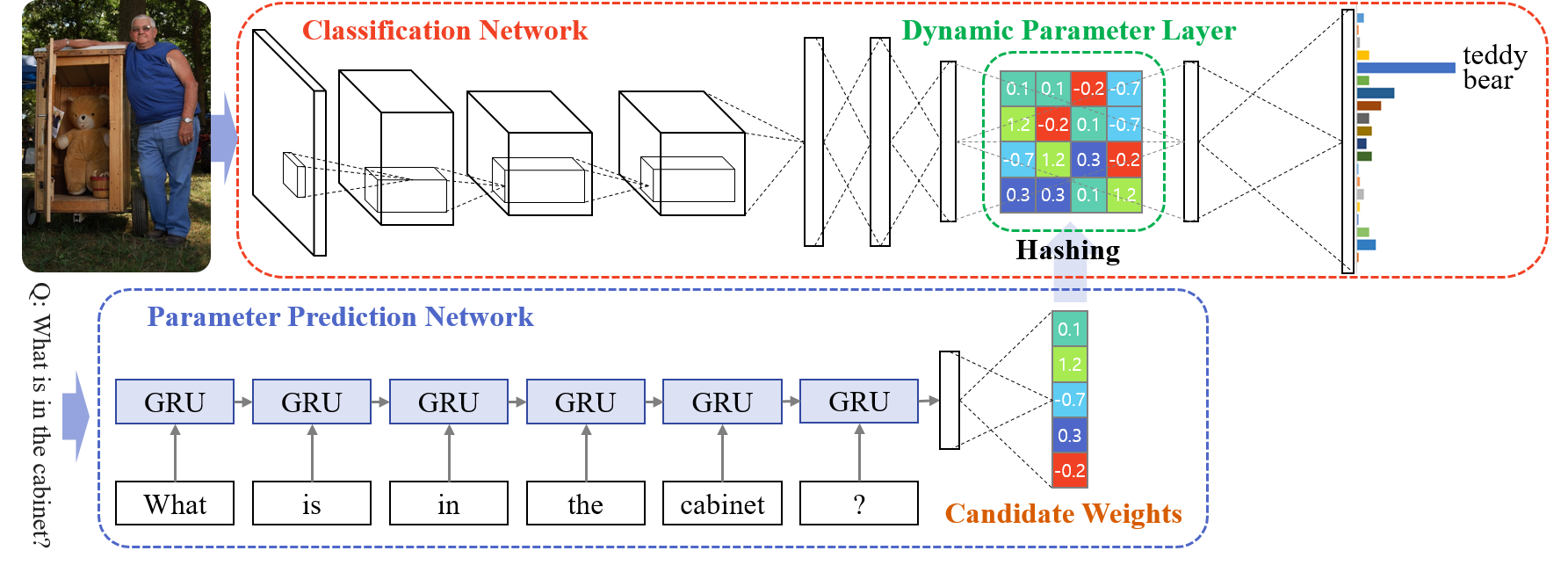
- arxiv: http://arxiv.org/abs/1511.05756
- github: https://github.com/HyeonwooNoh/DPPnet
- project page: http://cvlab.postech.ac.kr/research/dppnet/
Neural Generative Question Answering
Stacked Attention Networks for Image Question Answering
Ask, Attend and Answer: Exploring Question-Guided Spatial Attention for Visual Question Answering
Simple Baseline for Visual Question Answering
- intro: Facebook AI Research. Bag-of-word
- arxiv: http://arxiv.org/abs/1512.02167
- github: https://github.com/metalbubble/VQAbaseline
- demo: http://visualqa.csail.mit.edu/
MovieQA: Understanding Stories in Movies through Question-Answering
- intro: CVPR 2016
- project page: http://movieqa.cs.toronto.edu/home/
- arxiv: http://arxiv.org/abs/1512.02902
- gtihub: https://github.com/makarandtapaswi/MovieQA_CVPR2016/
Deeper LSTM+ normalized CNN for Visual Question Answering
- intro: “This current code can get 58.16 on Open-Ended and 63.09 on Multiple-Choice on test-standard split”
- github: https://github.com/VT-vision-lab/VQA_LSTM_CNN
A Neural Network for Factoid Question Answering over Paragraphs
- project page: http://cs.umd.edu/~miyyer/qblearn/
- paper: https://cs.umd.edu/~miyyer/pubs/2014_qb_rnn.pdf
- code+data: https://cs.umd.edu/~miyyer/qblearn/qanta.tar.gz
Learning to Compose Neural Networks for Question Answering
- intro: NAACL 2016 Best paper
- arxiv: http://arxiv.org/abs/1601.01705
Generating Natural Questions About an Image
Question Answering on Freebase via Relation Extraction and Textual Evidence
- intro: ACL 2016
- arxiv: https://arxiv.org/abs/1603.00957
- github: https://github.com/syxu828/QuestionAnsweringOverFB
Generating Factoid Questions With Recurrent Neural Networks: The 30M Factoid Question-Answer Corpus
Character-Level Question Answering with Attention
- arxiv: http://arxiv.org/abs/1604.00727
- comment(by @Wenpeng_Yin): “fancy model with minor improvement”
A Focused Dynamic Attention Model for Visual Question Answering
Visual Question Answering Literature Survey
The DIY Guide to Visual Question Answering
Question Answering via Integer Programming over Semi-Structured Knowledge
- arxiv: http://arxiv.org/abs/1604.06076
- github: https://github.com/allenai/tableilp
- youtube: https://www.youtube.com/watch?v=7NS53icQRrs
Hierarchical Question-Image Co-Attention for Visual Question Answering
Multimodal Residual Learning for Visual QA
Simple Question Answering by Attentive Convolutional Neural Network
Human Attention in Visual Question Answering: Do Humans and Deep Networks Look at the Same Regions?

Simple and Effective Question Answering with Recurrent Neural Networks
Analyzing the Behavior of Visual Question Answering Models
Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding
Deep Language Modeling for Question Answering using Keras
- blog: http://benjaminbolte.com/blog/2016/keras-language-modeling.html
- github: https://github.com/codekansas/keras-language-modeling
Interpreting Visual Question Answering Models
The Color of the Cat is Gray: 1 Million Full-Sentences Visual Question Answering
- intro: FSVQA
- arxiv: http://arxiv.org/abs/1609.06657
Tutorial on Answering Questions about Images with Deep Learning
- intro: The tutorial was presented at ‘2nd Summer School on Integrating Vision and Language: Deep Learning’ in Malta, 2016
- arxiv: https://arxiv.org/abs/1610.01076
Hadamard Product for Low-rank Bilinear Pooling
Open-Ended Visual Question-Answering
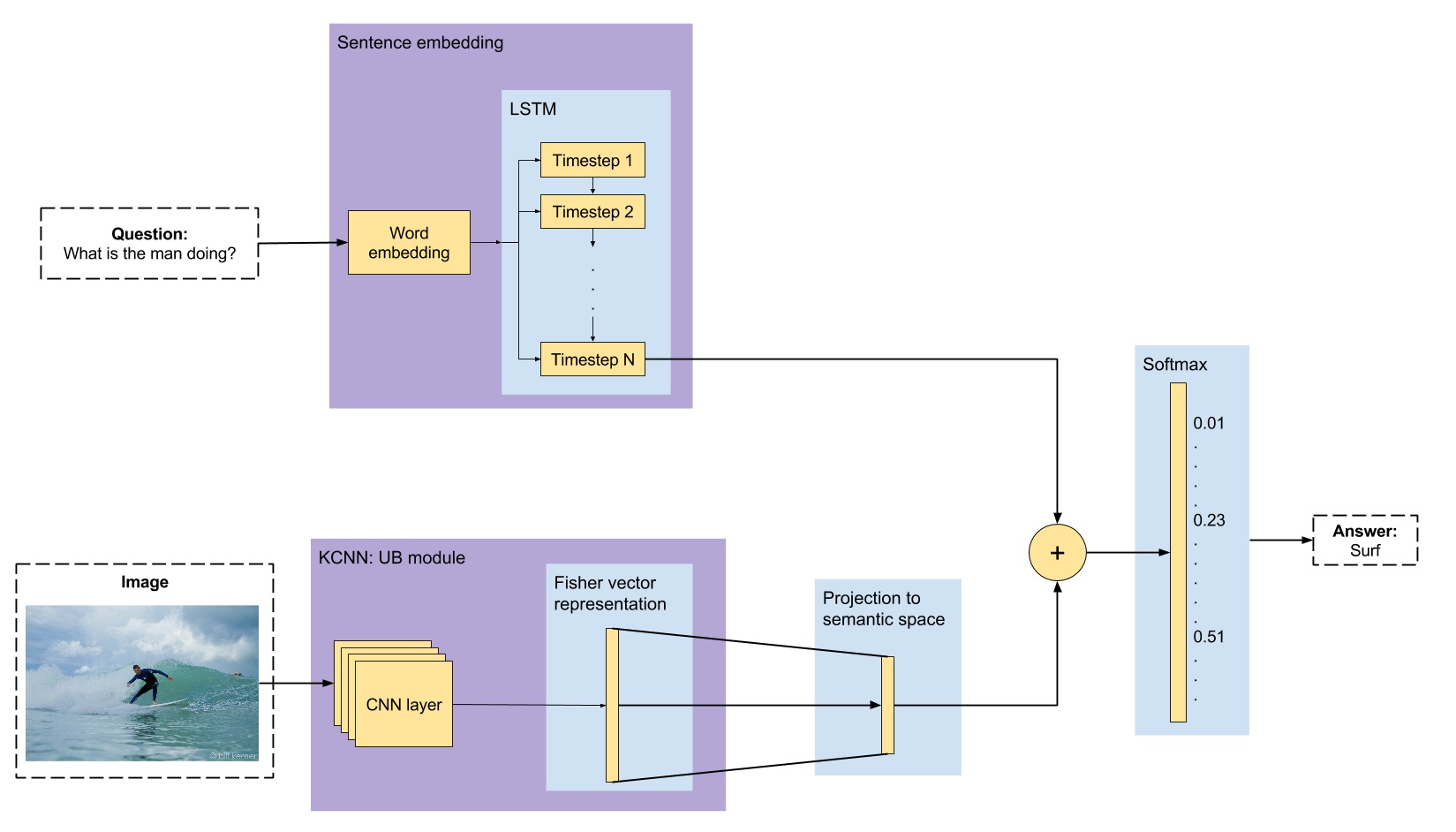
- intro: Bachelor thesis report graded with A with honours at ETSETB Telecom BCN school, Universitat Polit`ecnica de Catalunya (UPC). June 2016
- project page: http://imatge-upc.github.io/vqa-2016-cvprw/
- arxiv: https://arxiv.org/abs/1610.02692
- slides: http://www.slideshare.net/xavigiro/openended-visual-questionanswering
- github: https://github.com/imatge-upc/vqa-2016-cvprw
Deep Learning for Question Answering
- intro: UMD. Mohit Iyyer.
- intro: Recurrent Neural Networks, Recursive Neural Network
- slides: http://cs.umd.edu/~miyyer/data/deepqa.pdf
Dual Attention Networks for Multimodal Reasoning and Matching
Dynamic Coattention Networks For Question Answering
State of the art deep learning model for question answering
Zero-Shot Visual Question Answering
Image-Grounded Conversations: Multimodal Context for Natural Question and Response Generation
- intro: University of Rochester & Microsoft & University College London
- arxiv: https://arxiv.org/abs/1701.08251
Question Answering through Transfer Learning from Large Fine-grained Supervision Data
- intro: Seoul National University & University of Washington
- arxiv: https://arxiv.org/abs/1702.02171
Question Answering from Unstructured Text by Retrieval and Comprehension
- arxiv: https://arxiv.org/abs/1703.08885
- notes: https://theneuralperspective.com/2017/04/26/question-answering-from-unstructured-text-by-retrieval-and-comprehension/
Show, Ask, Attend, and Answer: A Strong Baseline For Visual Question Answering
- intro: Google Research
- arxiv: https://arxiv.org/abs/1704.03162
Learning to Reason: End-to-End Module Networks for Visual Question Answering
- intro: UC Berkeley, Boston University
- arxiv: https://arxiv.org/abs/1704.05526
TGIF-QA: Toward Spatio-Temporal Reasoning in Visual Question Answering
- intro: CVPR 2017.Seoul National University & Yahoo Research
- arxiv: https://arxiv.org/abs/1704.04497
- github: https://github.com/YunseokJANG/tgif-qa
Question Answering on Knowledge Bases and Text using Universal Schema and Memory Networks
- intro: ACL 2017 (short)
- project page: https://rajarshd.github.io/TextKBQA/
- arxiv: https://arxiv.org/abs/1704.08384
- github: https://github.com/rajarshd/TextKBQA
Learning Convolutional Text Representations for Visual Question Answering
Compact Tensor Pooling for Visual Question Answering
https://arxiv.org/abs/1706.06706
Long-Term Memory Networks for Question Answering
- intro: SUNY Buffalo & LinkedIn & LinkedIn
- arxiv: https://arxiv.org/abs/1707.01961
Bottom-Up and Top-Down Attention for Image Captioning and VQA
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
- intro: Winner of the Visual Question Answering Challenge at CVPR 2017
- project page: http://www.panderson.me/up-down-attention/
- arxiv: https://arxiv.org/abs/1707.07998
- paper: http://www.panderson.me/images/1707.07998-up-down.pdf
- github: https://github.com//peteanderson80/bottom-up-attention
Structured Attentions for Visual Question Answering
- intro: ICCV 2017
- arxiv: https://arxiv.org/abs/1708.02071
- github: https://github.com/zhuchen03/vqa-sva
Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge
- intro: Winner of the 2017 Visual Question Answering (VQA) Challenge at CVPR
- intro: The University of Adelaide & Australian National University & Microsoft Research
- arxiv: https://arxiv.org/abs/1708.02711
MemexQA: Visual Memex Question Answering
- intro: Carnegie Mellon University, Customer Service AI, Yahoo
- project page: https://memexqa.cs.cmu.edu/
- arxiv: https://arxiv.org/abs/1708.01336
Automatic Question-Answering Using A Deep Similarity Neural Network
- intro: New York University & AT&T Research Labs
- arxiv: https://arxiv.org/abs/1708.01713
Question Dependent Recurrent Entity Network for Question Answering
- intro: University of Pisa
- arxiv: https://arxiv.org/abs/1707.07922
- github: https://github.com/andreamad8/QDREN
Visual Question Generation as Dual Task of Visual Question Answering
https://arxiv.org/abs/1709.07192
A Read-Write Memory Network for Movie Story Understanding
- intro: ICCV 2017
- arxiv: https://arxiv.org/abs/1709.09345
iVQA: Inverse Visual Question Answering
https://arxiv.org/abs/1710.03370
DCN+: Mixed Objective and Deep Residual Coattention for Question Answering
- intro: Salesforce Research
- arxiv: https://arxiv.org/abs/1711.00106
- github: https://github.com/mjacar/tensorflow-dcn-plus
High-Order Attention Models for Visual Question Answering
- intro: NIPS 2017
- arxiv: https://arxiv.org/abs/1711.04323
Asking the Difficult Questions: Goal-Oriented Visual Question Generation via Intermediate Rewards
- intro: The University of Adelaide & University of Technology Sydney & Nanjing University of Science and Technology
- arxiv: https://arxiv.org/abs/1711.07614
Visual Question Answering as a Meta Learning Task
https://arxiv.org/abs/1711.08105
Embodied Question Answering
- intro: Georgia Institute of Technology & Facebook AI Research
- project page: https://embodiedqa.org/
- arxiv: https://arxiv.org/abs/1711.11543
- github: https://github.com/facebookresearch/EmbodiedQA
Learning by Asking Questions
https://arxiv.org/abs/1712.01238
Interpretable Counting for Visual Question Answering
https://arxiv.org/abs/1712.08697
Structured Triplet Learning with POS-tag Guided Attention for Visual Question Answering
DVQA: Understanding Data Visualizations via Question Answering
- intro: RIT & Adobe Research
- arxiv: https://arxiv.org/abs/1801.08163
Object-based reasoning in VQA
- intro: WACV 2018
- arxiv: https://arxiv.org/abs/1801.09718
Dual Recurrent Attention Units for Visual Question Answering
https://arxiv.org/abs/1802.00209
Differential Attention for Visual Question Answering
- intro: CVPR 2018
- arxiv: https://arxiv.org/abs/1804.00298
Question Type Guided Attention in Visual Question Answering
https://arxiv.org/abs/1804.02088
Movie Question Answering: Remembering the Textual Cues for Layered Visual Contents
- intro: AAAI 2018
- arxiv: https://arxiv.org/abs/1804.09412
Reciprocal Attention Fusion for Visual Question Answering
https://arxiv.org/abs/1805.04247
Learning to Count Objects in Natural Images for Visual Question Answering
- intro: ICLR 2018
- arxiv: https://arxiv.org/abs/1802.05766
Bilinear Attention Networks
- intro: CVPR 2018. Seoul National University
- arxiv: https://arxiv.org/abs/1805.07932
- slides: https://bi.snu.ac.kr/~jhkim/slides/bilinear%20attention%20networks_8min.pdf
- github(official, PyTorch): https://github.com/jnhwkim/ban-vqa
Reproducibility Report for “Learning To Count Objects In Natural Images For Visual Question Answering”
https://arxiv.org/abs/1805.08174
Cross-Dataset Adaptation for Visual Question Answering
- intro: CVPR 2018
- arxiv: https://arxiv.org/abs/1806.03726
Learning Answer Embeddings for Visual Question Answering
- intro: CVPR 2018
- arxiv: https://arxiv.org/abs/1806.03724
Learning Visual Question Answering by Bootstrapping Hard Attention
- intro: ECCV 2018
- axrxiv: https://arxiv.org/abs/1808.00300
Question-Guided Hybrid Convolution for Visual Question Answering
- intro: ECCV 2018
- arxiv: https://arxiv.org/abs/1808.02632
Interpretable Visual Question Answering by Reasoning on Dependency Trees
https://arxiv.org/abs/1809.01810
The Visual QA Devil in the Details: The Impact of Early Fusion and Batch Norm on CLEVR
- intro: ECCV 2018 Workshop on Shortcomings in Vision and Language
- arxiv: https://arxiv.org/abs/1809.04482
Knowing Where to Look? Analysis on Attention of Visual Question Answering System
- intro: ECCV SiVL Workshop paper
- arxiv: https://arxiv.org/abs/1810.03821
VQA with no questions-answers training
https://arxiv.org/abs/1811.08481
Visual Commonsense R-CNN
- intro: CVPR 2020
- arxiv: https://arxiv.org/abs/2002.12204
Video Question Answering
DeepStory: Video Story QA by Deep Embedded Memory Networks
- intro: IJCAI 2017. Seoul National University
- arxiv: https://arxiv.org/abs/1707.00836
Video Question Answering via Attribute-Augmented Attention Network Learning
- intro: SIGIR 2017
- arxiv: https://arxiv.org/abs/1707.06355
Leveraging Video Descriptions to Learn Video Question Answering
- intro: AAAI 2017
- arxiv: https://arxiv.org/abs/1611.04021
A Joint Sequence Fusion Model for Video Question Answering and Retrieval
- intro: ECCV 2018
- arixv: https://arxiv.org/abs/1808.02559
Projects
VQA Demo: Visual Question Answering Demo on pretrained model
deep-qa: Implementation of the Convolution Neural Network for factoid QA on the answer sentence selection task
YodaQA: A Question Answering system built on top of the Apache UIMA framework
- homepage: http://ailao.eu/yodaqa/
- github: https://github.com/brmson/yodaqa
insuranceQA-cnn-lstm: tensorflow and theano cnn code for insurance QA(question Answer matching)
Tensorflow Implementation of Deeper LSTM+ normalized CNN for Visual Question Answering

Visual Question Answering with Keras
- project page: https://anantzoid.github.io/VQA-Keras-Visual-Question-Answering/
- github: https://github.com/anantzoid/VQA-Keras-Visual-Question-Answering
Deep Learning Models for Question Answering with Keras
GuessWhat?! Visual object discovery through multi-modal dialogue
- intro: University of Montreal & Univ. Lille & Google DeepMind & Twitter
- arxiv: https://arxiv.org/abs/1611.08481
Deep QA: Using deep learning to answer Aristo’s science questions
Visual Question Answering in Pytorch
https://github.com/Cadene/vqa.pytorch
Dataset
Visual7W: Grounded Question Answering in Images

- homepage: http://web.stanford.edu/~yukez/visual7w/
- github: https://github.com/yukezhu/visual7w-toolkit
- github: https://github.com/yukezhu/visual7w-qa-models
Resources
Awesome Visual Question Answering
