Video Applications
Papers
You Lead, We Exceed: Labor-Free Video Concept Learningby Jointly Exploiting Web Videos and Images
- intro: CVPR 2016
- intro: Lead–Exceed Neural Network (LENN), LSTM
- paper: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/06/CVPR16_webly_final.pdf
Video Fill in the Blank with Merging LSTMs
- intro: for Large Scale Movie Description and Understanding Challenge (LSMDC) 2016, “Movie fill-in-the-blank” Challenge, UCF_CRCV
- intro: Video-Fill-in-the-Blank (ViFitB)
- arxiv: https://arxiv.org/abs/1610.04062
Video Pixel Networks
- intro: Google DeepMind
- arxiv: https://arxiv.org/abs/1610.00527
Robust Video Synchronization using Unsupervised Deep Learning
Video Propagation Networks
- intro: CVPR 2017. Max Planck Institute for Intelligent Systems & Bernstein Center for Computational Neuroscience
- project page: https://varunjampani.github.io/vpn/
- arxiv: https://arxiv.org/abs/1612.05478
- github(Caffe): https://github.com/varunjampani/video_prop_networks
Video Frame Synthesis using Deep Voxel Flow
- project page: https://liuziwei7.github.io/projects/VoxelFlow.html
- arxiv: https://arxiv.org/abs/1702.02463
Optimizing Deep CNN-Based Queries over Video Streams at Scale
- intro: Stanford InfoLab
- keywords: NoScope. difference detectors, specialized models
- arxiv: https://arxiv.org/abs/1703.02529
- github: https://github.com/stanford-futuredata/noscope
- github: https://github.com/stanford-futuredata/tensorflow-noscope
NoScope: 1000x Faster Deep Learning Queries over Video
http://dawn.cs.stanford.edu/2017/06/22/noscope/
Unsupervised Visual-Linguistic Reference Resolution in Instructional Videos
- intro: CVPR 2017. Stanford University & University of Southern California
- arxiv: https://arxiv.org/abs/1703.02521
ProcNets: Learning to Segment Procedures in Untrimmed and Unconstrained Videos
https://arxiv.org/abs/1703.09788
Unsupervised Learning Layers for Video Analysis
- intro: Baidu Research
- intro: “The experiments demonstrated the potential applications of UL layers and online learning algorithm to head orientation estimation and moving object localization”
- arxiv: https://arxiv.org/abs/1705.08918
Look, Listen and Learn
- intro: DeepMind
- intro: “Audio-Visual Correspondence” learning
- arxiv: https://arxiv.org/abs/1705.08168
Video Imagination from a Single Image with Transformation Generation
- intro: Peking University
- arxiv: https://arxiv.org/abs/1706.04124
- github: https://github.com/gitpub327/VideoImagination
Learning to Learn from Noisy Web Videos
- intro: CVPR 2017. Stanford University & CMU & Simon Fraser University
- arxiv: https://arxiv.org/abs/1706.02884
Convolutional Long Short-Term Memory Networks for Recognizing First Person Interactions
- intro: Accepted on the second International Workshop on Egocentric Perception, Interaction and Computing(EPIC) at International Conference on Computer Vision(ICCV-17)
- arxiv: https://arxiv.org/abs/1709.06495
Learning Binary Residual Representations for Domain-specific Video Streaming
- intro: AAAI 2018
- project page: http://research.nvidia.com/publication/2018-02_Learning-Binary-Residual
- arxiv: https://arxiv.org/abs/1712.05087
Video Representation Learning Using Discriminative Pooling
- intro: CVPR 2018
- arxiv: https://arxiv.org/abs/1803.10628
Rethinking the Faster R-CNN Architecture for Temporal Action Localization
- intro: CVPR 2018
- arxiv: https://arxiv.org/abs/1804.07667
Deep Keyframe Detection in Human Action Videos
- intro: two-stream ConvNet
- arxiv: https://arxiv.org/abs/1804.10021
FFNet: Video Fast-Forwarding via Reinforcement Learning
- intro: CVPR 2018
- arxiv: https://arxiv.org/abs/1805.02792
Fast forwarding Egocentric Videos by Listening and Watching
https://arxiv.org/abs/1806.04620
Scanner: Efficient Video Analysis at Scale
- intro: CMU
- arxiv: https://arxiv.org/abs/1805.07339
Massively Parallel Video Networks
- intro: DeepMind & University of Oxford
- arxiv: https://arxiv.org/abs/1806.03863
Object Level Visual Reasoning in Videos
- intro: LIRIS & Facebook AI Research
- arxiv: https://arxiv.org/abs/1806.06157
Video Time: Properties, Encoders and Evaluation
- intro: BMVC 2018
- arxiv: https://arxiv.org/abs/1807.06980
Inserting Videos into Videos
- intro: CVPR 2019
- arxiv: https://arxiv.org/abs/1903.06571
Video Classification
Large-scale Video Classification with Convolutional Neural Networks
- intro: CVPR 2014
- project page: http://cs.stanford.edu/people/karpathy/deepvideo/
- paper: www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Karpathy_Large-scale_Video_Classification_2014_CVPR_paper.pdf
Exploiting Image-trained CNN Architectures for Unconstrained Video Classification
- intro: Video-level event detection. extracting deep features for each frame, averaging frame-level deep features
- arxiv: http://arxiv.org/abs/1503.04144
Beyond Short Snippets: Deep Networks for Video Classification
- intro: CNN + LSTM
- arxiv: http://arxiv.org/abs/1503.08909
- demo: http://pan.baidu.com/s/1eQ9zLZk
Modeling Spatial-Temporal Clues in a Hybrid Deep Learning Framework for Video Classification
- intro: ACM Multimedia, 2015
- arxiv: http://arxiv.org/abs/1504.01561
Video Content Recognition with Deep Learning
- author: Zuxuan Wu, Fudan University
- slides: http://vision.ouc.edu.cn/valse/slides/20160420/Zuxuan%20Wu%20-%20Video%20Content%20Recognition%20with%20Deep%20Learning-Zuxuan%20Wu.pdf
Video Content Recognition with Deep Learning
- author: Yu-Gang Jiang, Lab for Big Video Data Analytics (BigVid), Fudan University
- slides: http://www.yugangjiang.info/slides/DeepVideoTalk-2015.pdf
Efficient Large Scale Video Classification
- intro: Google
- arxiv: http://arxiv.org/abs/1505.06250
Fusing Multi-Stream Deep Networks for Video Classification
Learning End-to-end Video Classification with Rank-Pooling
- paper: http://jmlr.org/proceedings/papers/v48/fernando16.html
- paper: http://jmlr.csail.mit.edu/proceedings/papers/v48/fernando16.pdf
- summary(by Hugo Larochelle): http://www.shortscience.org/paper?bibtexKey=conf/icml/FernandoG16#hlarochelle
Deep Learning for Video Classification and Captioning
Fast Video Classification via Adaptive Cascading of Deep Models
Deep Feature Flow for Video Recognition
- intro: CVPR 2017
- intro: It provides a simple, fast, accurate, and end-to-end framework for video recognition (e.g., object detection and semantic segmentation in videos)
- arxiv: https://arxiv.org/abs/1611.07715
- github(official, MXNet): https://github.com/msracver/Deep-Feature-Flow
- youtube: https://www.youtube.com/watch?v=J0rMHE6ehGw
Large-Scale YouTube-8M Video Understanding with Deep Neural Networks
https://arxiv.org/abs/1706.04488
Deep Learning Methods for Efficient Large Scale Video Labeling
- intro: Solution to the Kaggle’s competition Google Cloud & YouTube-8M Video Understanding Challenge
- arxiv: https://arxiv.org/abs/1706.04572
- github: https://github.com/mpekalski/Y8M
Learnable pooling with Context Gating for video classification
- intro: CVPR17 Youtube 8M workshop. Kaggle 1st place
- arxiv: https://arxiv.org/abs/1706.06905
- github: https://github.com/antoine77340/LOUPE
Aggregating Frame-level Features for Large-Scale Video Classification
- intro: Youtube-8M Challenge, 4th place
- arxiv: https://arxiv.org/abs/1707.00803
Tensor-Train Recurrent Neural Networks for Video Classification
https://arxiv.org/abs/1707.01786
Hierarchical Deep Recurrent Architecture for Video Understanding
- intro: Classification Challenge Track paper in CVPR 2017 Workshop on YouTube-8M Large-Scale Video Understanding
- arxiv: https://arxiv.org/abs/1707.03296
Large-scale Video Classification guided by Batch Normalized LSTM Translator
- intro: CVPR2017 Workshop on Youtube-8M Large-scale Video Understanding
- arxiv: https://arxiv.org/abs/1707.04045
UTS submission to Google YouTube-8M Challenge 2017
- intro: CVPR’17 Workshop on YouTube-8M
- arxiv: https://arxiv.org/abs/1707.04143
- github: https://github.com/ffmpbgrnn/yt8m
A spatiotemporal model with visual attention for video classification
https://arxiv.org/abs/1707.02069
Cultivating DNN Diversity for Large Scale Video Labelling
- intro: CVPR 2017 Youtube-8M Workshop
- arxiv: https://arxiv.org/abs/1707.04272
Attention Transfer from Web Images for Video Recognition
- intro: ACM Multimedia, 2017
- arxiv: https://arxiv.org/abs/1708.00973
Non-local Neural Networks
- intro: CVPR 2018. CMU & Facebook AI Research
- arxiv: https://arxiv.org/abs/1711.07971
- github(Caffe2): https://github.com/facebookresearch/video-nonlocal-net
Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classification
https://arxiv.org/abs/1711.08200
Appearance-and-Relation Networks for Video Classification
Rethinking Spatiotemporal Feature Learning: Speed-Accuracy Trade-offs in Video Classification
- intro: ECCV 2018. Google Research & University of California San Diego
- arxiv: https://arxiv.org/abs/1712.04851
Long Activity Video Understanding using Functional Object-Oriented Network
https://arxiv.org/abs/1807.00983
Deep Architectures and Ensembles for Semantic Video Classification
https://arxiv.org/abs/1807.01026
Deep Discriminative Model for Video Classification
- intro: ECCV 2018
- arxiv: https://arxiv.org/abs/1807.08259
Deep Video Color Propagation
- intro: BMVC 2018
- arxuv: https://arxiv.org/abs/1808.03232
Non-local NetVLAD Encoding for Video Classification
- intro: ECCV 2018 workshop on YouTube-8M Large-Scale Video Understanding
- intro: Tencent AI Lab & Fudan University
- arxiv: https://arxiv.org/abs/1810.00207
Learnable Pooling Methods for Video Classification
- intro: Youtube 8M ECCV18 Workshop
- arxiv: https://arxiv.org/abs/1810.00530
- github: https://github.com/pomonam/LearnablePoolingMethods
NeXtVLAD: An Efficient Neural Network to Aggregate Frame-level Features for Large-scale Video Classification
- intro: ECCV 2018 workshop
- arxiv: https://arxiv.org/abs/1811.05014
- github: https://github.com/linrongc/youtube-8m
High Order Neural Networks for Video Classification
- intro: Fudan University, Carnegie Mellon University, Qiniu Inc., ByteDance AI Lab
- arxiv: https://arxiv.org/abs/1811.07519
TSM: Temporal Shift Module for Efficient Video Understanding
- intro: ICCV 2019
- intro: MIT & MIT-IBM Watson AI Lab
- arxiv: https://arxiv.org/abs/1811.08383
- github: https://github.com/mit-han-lab/temporal-shift-module
SlowFast Networks for Video Recognition
- intro: Facebook AI Research (FAIR)
- arxiv: https://arxiv.org/abs/1812.03982
Efficient Video Classification Using Fewer Frames
- intro: CVPR 2019
- arxiv: https://arxiv.org/abs/1902.10640
Video Classification with Channel-Separated Convolutional Networks
- intro: Facebook AI
- arxiv: https://arxiv.org/abs/1904.02811
Two-Stream Video Classification with Cross-Modality Attention
https://arxiv.org/abs/1908.00497
Action Detection / Activity Recognition
3d convolutional neural networks for human action recognition
Sequential Deep Learning for Human Action Recognition
Two-stream convolutional networks for action recognition in videos
Finding action tubes
- intro: “built action models from shape and motion cues. They start from the image proposals and select the motion salient subset of them and extract saptio-temporal features to represent the video using the CNNs.”
- arxiv: http://arxiv.org/abs/1411.6031
Hierarchical Recurrent Neural Network for Skeleton Based Action Recognition
Action Recognition with Trajectory-Pooled Deep-Convolutional Descriptors
- intro: CVPR 2015. TDD
- paper: www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Wang_Action_Recognition_With_2015_CVPR_paper.pdf
- ext: http://www.cv-foundation.org/openaccess/content_cvpr_2015/app/2B_105_ext.pdf
- poster: https://wanglimin.github.io/papers/WangQT_CVPR15_Poster.pdf
- github: https://github.com/wanglimin/TDD
Action Recognition by Hierarchical Mid-level Action Elements
Contextual Action Recognition with R CNN
Towards Good Practices for Very Deep Two-Stream ConvNets
- arxiv: http://arxiv.org/abs/1507.02159
- github: https://github.com/yjxiong/caffe
Action Recognition using Visual Attention
- intro: LSTM / RNN
- arxiv: http://arxiv.org/abs/1511.04119
- project page: http://shikharsharma.com/projects/action-recognition-attention/
- github(Python/Theano): https://github.com/kracwarlock/action-recognition-visual-attention
End-to-end Learning of Action Detection from Frame Glimpses in Videos
- intro: CVPR 2016
- project page: http://ai.stanford.edu/~syyeung/frameglimpses.html
- arxiv: http://arxiv.org/abs/1511.06984
- paper: http://vision.stanford.edu/pdf/yeung2016cvpr.pdf
Multi-velocity neural networks for gesture recognition in videos
Active Learning for Online Recognition of Human Activities from Streaming Videos
Convolutional Two-Stream Network Fusion for Video Action Recognition
Deep, Convolutional, and Recurrent Models for Human Activity Recognition using Wearables
Unsupervised Semantic Action Discovery from Video Collections
Anticipating Visual Representations from Unlabeled Video
VideoLSTM Convolves, Attends and Flows for Action Recognition
Hierarchical Attention Network for Action Recognition in Videos (HAN)
Spatio-Temporal LSTM with Trust Gates for 3D Human Action Recognition
Connectionist Temporal Modeling for Weakly Supervised Action Labeling
CUHK & ETHZ & SIAT Submission to ActivityNet Challenge 2016
- intro: won the 1st place in the untrimmed video classification task of ActivityNet Challenge 2016. TSN
- arxiv: http://arxiv.org/abs/1608.00797
- github: https://github.com/yjxiong/anet2016-cuhk
Actionness Estimation Using Hybrid FCNs
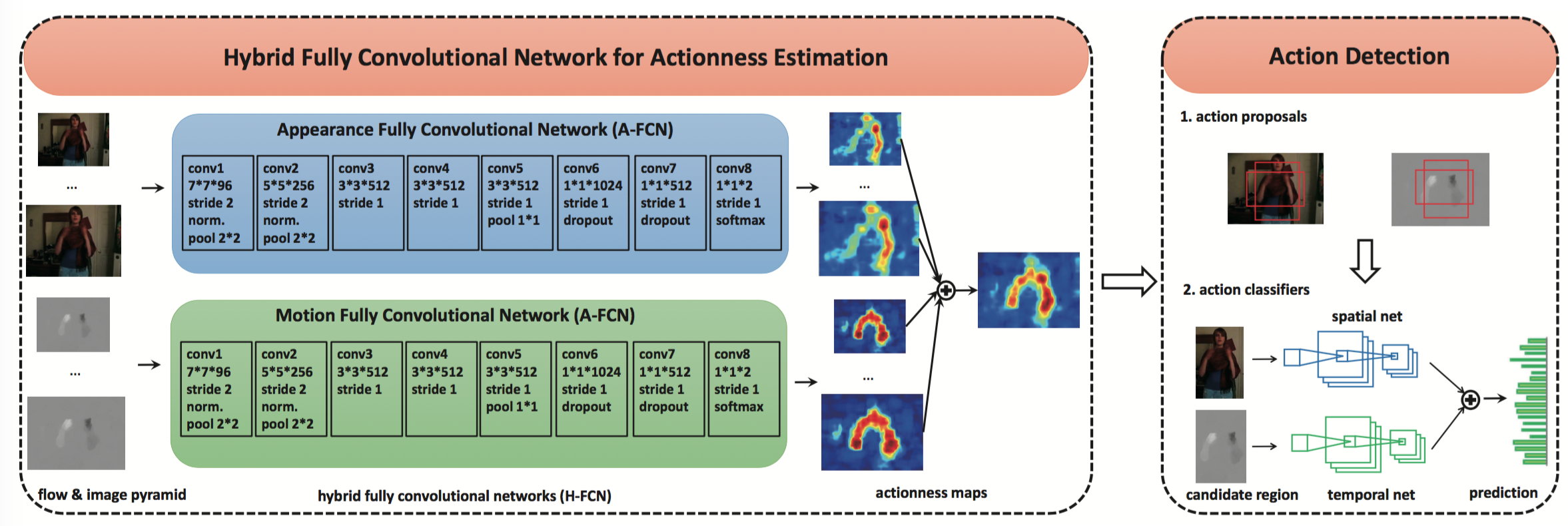
- intro: CVPR 2016. H-FCN
- project page: http://wanglimin.github.io/actionness_hfcn/index.html
- paper: http://wanglimin.github.io/papers/WangQTV_CVPR16.pdf
- github: https://github.com/wanglimin/actionness-estimation/
Real-time Action Recognition with Enhanced Motion Vector CNNs

- intro: CVPR 2016
- project page: http://zbwglory.github.io/MV-CNN/index.html
- paper: http://wanglimin.github.io/papers/ZhangWWQW_CVPR16.pdf
- github: https://github.com/zbwglory/MV-release
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
- intro: ECCV 2016. HMDB51: 69.4%, UCF101: 94.2%
- arxiv: http://arxiv.org/abs/1608.00859
- paper: http://wanglimin.github.io/papers/WangXWQLTV_ECCV16.pdf
- github: https://github.com/yjxiong/temporal-segment-networks
Temporal Segment Networks for Action Recognition in Videos
- intro: An extension of submission http://arxiv.org/abs/1608.00859
- arxiv: https://arxiv.org/abs/1705.02953
Hierarchical Attention Network for Action Recognition in Videos
DeepCAMP: Deep Convolutional Action & Attribute Mid-Level Patterns
- intro: CVPR 2016
- arxiv: http://arxiv.org/abs/1608.03217
Depth2Action: Exploring Embedded Depth for Large-Scale Action Recognition
Dynamic Image Networks for Action Recognition
- intro: CVPR 2016
- arxiv: http://users.cecs.anu.edu.au/~sgould/papers/cvpr16-dynamic_images.pdf
- github: https://github.com/hbilen/dynamic-image-nets
Human Action Recognition without Human
Temporal Convolutional Networks: A Unified Approach to Action Segmentation
- arxiv: http://arxiv.org/abs/1608.08242
- ECCV 2016 workshop: http://bravenewmotion.github.io/
Temporal Activity Detection in Untrimmed Videos with Recurrent Neural Networks
- intro: Bachelor Thesis Report at ETSETB TelecomBCN
- project page: https://imatge-upc.github.io/activitynet-2016-cvprw/
- arxiv: http://arxiv.org/abs/1608.08128
- github: https://github.com/imatge-upc/activitynet-2016-cvprw
Sequential Deep Trajectory Descriptor for Action Recognition with Three-stream CNN
Semi-Coupled Two-Stream Fusion ConvNets for Action Recognition at Extremely Low Resolutions
Spatiotemporal Residual Networks for Video Action Recognition
- intro: NIPS 2016
- arxiv: https://arxiv.org/abs/1611.02155
Action Recognition Based on Joint Trajectory Maps Using Convolutional Neural Networks
Deep Recurrent Neural Network for Mobile Human Activity Recognition with High Throughput
Joint Network based Attention for Action Recognition
Temporal Convolutional Networks for Action Segmentation and Detection
AdaScan: Adaptive Scan Pooling in Deep Convolutional Neural Networks for Human Action Recognition in Videos
ActionFlowNet: Learning Motion Representation for Action Recognition
Higher-order Pooling of CNN Features via Kernel Linearization for Action Recognition
- intro: Australian Center for Robotic Vision & Data61/CSIRO
- arxiv: https://arxiv.org/abs/1701.05432
Tube Convolutional Neural Network (T-CNN) for Action Detection in Videos
https://arxiv.org/abs/1703.10664
Temporal Action Detection with Structured Segment Networks
- project page: http://yjxiong.me/others/ssn/
- arxiv: https://arxiv.org/abs/1704.06228
- github: https://github.com/yjxiong/action-detection
Recurrent Residual Learning for Action Recognition
https://arxiv.org/abs/1706.08807
Hierarchical Multi-scale Attention Networks for Action Recognition
https://arxiv.org/abs/1708.07590
Two-stream Flow-guided Convolutional Attention Networks for Action Recognition
- intro: International Conference of Computer Vision Workshop (ICCVW), 2017
- arxiv: https://arxiv.org/abs/1708.09268
Action Classification and Highlighting in Videos
https://arxiv.org/abs/1708.09522
Real-Time Action Detection in Video Surveillance using Sub-Action Descriptor with Multi-CNN
https://arxiv.org/abs/1710.03383
End-to-end Video-level Representation Learning for Action Recognition
- keywords: Deep networks with Temporal Pyramid Pooling (DTPP)
- arxiv: https://arxiv.org/abs/1711.04161
Fully-Coupled Two-Stream Spatiotemporal Networks for Extremely Low Resolution Action Recognition
- intro: WACV 2018
- arxiv: https://arxiv.org/abs/1801.03983
DiscrimNet: Semi-Supervised Action Recognition from Videos using Generative Adversarial Networks
https://arxiv.org/abs/1801.07230
A Fusion of Appearance based CNNs and Temporal evolution of Skeleton with LSTM for Daily Living Action Recognition
https://arxiv.org/abs/1802.00421
Real-Time End-to-End Action Detection with Two-Stream Networks
https://arxiv.org/abs/1802.08362
A Closer Look at Spatiotemporal Convolutions for Action Recognition
- intro: CVPR 2018. Facebook Research
- intro: R(2+1)D and Mixed-Convolutions for Action Recognition.
- project page: https://dutran.github.io/R2Plus1D/
- arxiv: https://arxiv.org/abs/1711.11248
- github: https://github.com/facebookresearch/R2Plus1D
VideoCapsuleNet: A Simplified Network for Action Detection
https://arxiv.org/abs/1805.08162
Where and When to Look? Spatio-temporal Attention for Action Recognition in Videos
https://arxiv.org/abs/1810.04511
Relational Long Short-Term Memory for Video Action Recognition
https://arxiv.org/abs/1811.07059
Temporal Recurrent Networks for Online Action Detection
https://arxiv.org/abs/1811.073910
Video Action Transformer Network
- intro: Carnegie Mellon University & DeepMind & University of Oxford
- intro: Ranked first on the AVA (computer vision only) leaderboard of the ActivityNet Challenge 2018
- project page: https://rohitgirdhar.github.io/ActionTransformer/
- arxiv: https://arxiv.org/abs/1812.02707
D3D: Distilled 3D Networks for Video Action Recognition
- intro: Google & University of Michigan & Princeton University
- arxiv: https://arxiv.org/abs/1812.08249
TACNet: Transition-Aware Context Network for Spatio-Temporal Action Detection
- intro: CVPR 2019
- arxiv: https://arxiv.org/abs/1905.13417
Deformable Tube Network for Action Detection in Videos
https://arxiv.org/abs/1907.01847
You Only Watch Once: A Unified CNN Architecture for Real-Time Spatiotemporal Action Localization
https://arxiv.org/abs/1911.06644
TubeR: Tube-Transformer for Action Detection
- intro: University of Amsterdam & Amazon Web Service
- arxiv: https://arxiv.org/abs/2104.00969
Revisiting Skeleton-based Action Recognition
https://arxiv.org/abs/2104.13586
End-to-end Temporal Action Detection with Transformer
- arxiv: https://arxiv.org/abs/2106.10271
- github: https://github.com/xlliu7/TadTR
OadTR: Online Action Detection with Transformers
VideoLightFormer: Lightweight Action Recognition using Transformers
https://arxiv.org/abs/2107.00451
Projects
A Torch Library for Action Recognition and Detection Using CNNs and LSTMs
- intro: CS231n student project report
- paper: http://cs231n.stanford.edu/reports2016/221_Report.pdf
- github: https://github.com/garythung/torch-lrcn
2016 ActivityNet action recognition challenge. CNN + LSTM approach. Multi-threaded loading.
LSTM for Human Activity Recognition
- github: https://github.com/guillaume-chevalier/LSTM-Human-Activity-Recognition/
- github(MXNet): https://github.com/Ldpe2G/DeepLearningForFun/tree/master/Mxnet-Scala/HumanActivityRecognition
Scanner: Efficient Video Analysis at Scale
- intro: Locate and recognize faces in a video, Detect shots in a film, Search videos by image
- github: https://github.com/scanner-research/scanner
Charades Starter Code for Activity Classification and Localization
- intro: Activity Recognition Algorithms for the Charades Dataset
- github: https://github.com/gsig/charades-algorithms
NonLocalNetwork and Sequeeze-Excitation Network
- intro: MXNet implementation of Non-Local and Squeeze-Excitation network
- github: https://github.com/WillSuen/NonLocalandSEnet
Event Recognition
TagBook: A Semantic Video Representation without Supervision for Event Detection
AENet: Learning Deep Audio Features for Video Analysis
- arxiv: https://arxiv.org/abs/1701.00599
- github: https://github.com/znaoya/aenet
Event Detection
DevNet: A Deep Event Network for Multimedia Event Detection and Evidence Recounting
- paper: http://120.52.72.47/winsty.net/c3pr90ntcsf0/papers/devnet.pdf
- paper: http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Gan_DevNet_A_Deep_2015_CVPR_paper.pdf
Detecting events and key actors in multi-person videos

- intro: CVPR 2016
- arxiv: http://arxiv.org/abs/1511.02917
- paper: www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Ramanathan_Detecting_Events_and_CVPR_2016_paper.pdf
- paper: http://vision.stanford.edu/pdf/johnson2016cvpr.pdf
- blog: http://www.leiphone.com/news/201606/l1TKIRFLO3DUFNNu.html
Deep Convolutional Neural Networks and Data Augmentation for Acoustic Event Detection
- intro: INTERSPEECH 2016
- arxiv: https://arxiv.org/abs/1604.07160
Efficient Action Detection in Untrimmed Videos via Multi-Task Learning
Joint Event Detection and Description in Continuous Video Streams
- intro: Joint Event Detection and Description Network (JEDDi-Net)
- arxiv: https://arxiv.org/abs/1802.10250
Abnormality / Anomaly Detection
Fully Convolutional Neural Network for Fast Anomaly Detection in Crowded Scenes
Anomaly Detection in Video Using Predictive Convolutional Long Short-Term Memory Networks
- intro: Rochester Institute of Technology
- arxiv: https://arxiv.org/abs/1612.00390
Abnormal Event Detection in Videos using Spatiotemporal Autoencoder
- arxiv: https://arxiv.org/abs/1701.01546
- github: https://github.com/yshean/abnormal-spatiotemporal-ae
Abnormal Event Detection in Videos using Generative Adversarial Nets
- intro: Best Paper / Student Paper Award Finalist, IEEE International Conference on Image Processing (ICIP), 2017
- arxiv: https://arxiv.org/abs/1708.09644
Joint Detection and Recounting of Abnormal Events by Learning Deep Generic Knowledge
- intro: ICCV 2017
- arxiv: https://arxiv.org/abs/1709.09121
An overview of deep learning based methods for unsupervised and semi-supervised anomaly detection in videos
- intro: Uncanny Vision Solutions
- arxiv: https://arxiv.org/abs/1801.03149
STAN: Spatio-Temporal Adversarial Networks for Abnormal Event Detection
- intro: ICASSP 2018
- arxiv: https://arxiv.org/abs/1804.08381
Video Anomaly Detection and Localization via Gaussian Mixture Fully Convolutional Variational Autoencoder
https://arxiv.org/abs/1805.11223
Attentioned Convolutional LSTM InpaintingNetwork for Anomaly Detection in Videos
https://arxiv.org/abs/1811.10228
Video Prediction
Deep multi-scale video prediction beyond mean square error
- intro: ICLR 2016
- arxiv: http://arxiv.org/abs/1511.05440
- github: https://github.com/coupriec/VideoPredictionICLR2016
- github(TensorFlow): https://github.com/dyelax/Adversarial_Video_Generation
- demo: http://cs.nyu.edu/~mathieu/iclr2016.html
Unsupervised Learning for Physical Interaction through Video Prediction
- intro: NIPS 2016
- arxiv: https://arxiv.org/abs/1605.07157
- github: https://github.com/tensorflow/models/tree/master/video_prediction
Generating Videos with Scene Dynamics
- intro: NIPS 2016
- intro: The model learns to generate tiny videos using adversarial networks
- project page: http://web.mit.edu/vondrick/tinyvideo/
- paper: http://web.mit.edu/vondrick/tinyvideo/paper.pdf
- github: https://github.com/cvondrick/videogan
PredNet
Deep Predictive Coding Networks for Video Prediction and Unsupervised Learning
- project page: https://coxlab.github.io/prednet/
- arxiv: http://arxiv.org/abs/1605.08104
- github: https://github.com/coxlab/prednet
- github: https://github.com/e-lab/torch-prednet
Diversity encouraged learning of unsupervised LSTM ensemble for neural activity video prediction
Video Ladder Networks
- inro: NIPS 2016 workshop on ML for Spatiotemporal Forecasting
- arxiv: https://arxiv.org/abs/1612.01756
Unsupervised Learning of Long-Term Motion Dynamics for Videos
- intro: Stanford University
- arxiv: https://arxiv.org/abs/1701.01821
One-Step Time-Dependent Future Video Frame Prediction with a Convolutional Encoder-Decoder Neural Network
- intro: NCCV 2016
- arxiv: https://arxiv.org/abs/1702.04125
Fully Context-Aware Video Prediction
- intro: ETH Zurich & NNAISENSE
- keywords: unsupervised learning through video prediction, Parallel Multi-Dimensional LSTM
- project page: https://sites.google.com/view/contextvp
- arxiv: https://arxiv.org/abs/1710.08518
Novel Video Prediction for Large-scale Scene using Optical Flow
- intro: University of Victoria & Tongji University & Horizon Robotics
- arxiv: https://arxiv.org/abs/1805.12243
Video Tagging
Automatic Image and Video Tagging

Tagging YouTube music videos with deep learning - Alexandre Passant
- keywords: Clarifai’s deep learning API
- blog: http://apassant.net/2015/07/03/tagging-youtube-music-clarifai-deep-learning/
Shot Boundary Detection
Large-scale, Fast and Accurate Shot Boundary Detection through Spatio-temporal Convolutional Neural Networks
https://arxiv.org/abs/1705.03281
Ridiculously Fast Shot Boundary Detection with Fully Convolutional Neural Networks
- intro: obtains state-of-the-art results while running at an unprecedented speed of more than 120x real-time.
- arxiv: https://arxiv.org/abs/1705.08214
Video Action Segmentation
TricorNet: A Hybrid Temporal Convolutional and Recurrent Network for Video Action Segmentation
- intro: University of Rochester
- arxiv: https://arxiv.org/abs/1705.07818
Video2GIF
Video2GIF: Automatic Generation of Animated GIFs from Video (Robust Deep RankNet)
- intro: 3D CNN, ranking model, Huber loss, 100K GIFs/video sources dataset
- arxiv: http://arxiv.org/abs/1605.04850
- github(dataset): https://github.com/gyglim/video2gif_dataset
- results: http://video2gif.info/
- demo site: http://people.ee.ethz.ch/~gyglim/work_public/autogif/
- review: http://motherboard.vice.com/read/these-fire-gifs-were-made-by-artificial-intelligence-yahoo
Creating Animated GIFs Automatically from Video
https://yahooresearch.tumblr.com/post/148009705216/creating-animated-gifs-automatically-from-video
GIF2Video: Color Dequantization and Temporal Interpolation of GIF images
- intro: Stony Brook University & Megvii Research USA & UCLA
- arxiv: https://arxiv.org/abs/1901.02840
Video2Speech
Vid2speech: Speech Reconstruction from Silent Video
- intro: ICASSP 2017
- project page: http://www.vision.huji.ac.il/vid2speech/
- arxiv: https://arxiv.org/abs/1701.00495
- github(official): https://github.com/arielephrat/vid2speech
Video Captioning
http://handong1587.github.io/deep_learning/2015/10/09/image-video-captioning.html#video-captioning
Video Summarization
Video summarization produces a short summary of a full-length video and ideally encapsulates its most informative parts, alleviates the problem of video browsing, editing and indexing.
Video Summarization with Long Short-term Memory
DeepVideo: Video Summarization using Temporal Sequence Modelling
- intro: CS231n student project report
- paper: http://cs231n.stanford.edu/reports2016/216_Report.pdf
Semantic Video Trailers
Video Summarization using Deep Semantic Features
- inro: ACCV 2016
- arxiv: http://arxiv.org/abs/1609.08758
CNN-Based Prediction of Frame-Level Shot Importance for Video Summarization
- intro: International Conference on new Trends in Computer Sciences (ICTCS), Amman-Jordan, 2017
- arxiv: https://arxiv.org/abs/1708.07023
Video Summarization with Attention-Based Encoder-Decoder Networks
https://arxiv.org/abs/1708.09545
Deep Reinforcement Learning for Unsupervised Video Summarization with Diversity-Representativeness Reward
- intro: AAAI 2018. Chinese Academy of Sciences & Queen Mary University of London
- project page: https://kaiyangzhou.github.io/project_vsumm_reinforce/index.html
- arxiv: https://arxiv.org/abs/1801.00054
- github: https://github.com//KaiyangZhou/vsumm-reinforce
Viewpoint-aware Video Summarization
- intro: CVPR 2018
- arxiv: https://arxiv.org/abs/1804.02843
DTR-GAN: Dilated Temporal Relational Adversarial Network for Video Summarization
https://arxiv.org/abs/1804.11228
Learning Video Summarization Using Unpaired Data
https://arxiv.org/abs/1805.12174
Video Summarization Using Fully Convolutional Sequence Networks
https://arxiv.org/abs/1805.10538
Video Summarisation by Classification with Deep Reinforcement Learning
- intro: BMVC 2018
- arxiv: https://arxiv.org/abs/1807.03089
Query-Conditioned Three-Player Adversarial Network for Video Summarization
- intro: BMVC 2018
- arxiv: https://arxiv.org/abs/1807.06677
Discriminative Feature Learning for Unsupervised Video Summarization
- intro: AAAI 2019
- arxiv: https://arxiv.org/abs/1811.09791
Rethinking the Evaluation of Video Summaries
- intro: CVPR 2019 poster
- arxiv: https://arxiv.org/abs/1903.11328
Video Highlight Detection
Unsupervised Extraction of Video Highlights Via Robust Recurrent Auto-encoders
- intro: ICCV 2015
- intro: rely on an assumption that highlights of an event category are more frequently captured in short videos than non-highlights
- arxiv: http://arxiv.org/abs/1510.01442
Highlight Detection with Pairwise Deep Ranking for First-Person Video Summarization
- keywords: wearable device
- paper: http://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Yao_Highlight_Detection_With_CVPR_2016_paper.pdf
- paper: http://research.microsoft.com/apps/pubs/default.aspx?id=264919
Using Deep Learning to Find Basketball Highlights

- blog: http://public.hudl.com/bits/archives/2015/06/05/highlights/?utm_source=tuicool&utm_medium=referral
Real-Time Video Highlights for Yahoo Esports
A Deep Ranking Model for Spatio-Temporal Highlight Detection from a 360 Video
- intro: AAAI 2018
- arxiv: https://arxiv.org/abs/1801.10312
PHD-GIFs: Personalized Highlight Detection for Automatic GIF Creation
- intro: Nanyang Technological University & Google Research, Zurich
- keywords: personalized highlight detection (PHD)
- arxiv: https://arxiv.org/abs/1804.06604
Video Understanding
Scale Up Video Understandingwith Deep Learning
- intro: 2016, Tsinghua University
- slides: iiis.tsinghua.edu.cn/~jianli/courses/ATCS2016spring/talk_chuang.pptx
Slicing Convolutional Neural Network for Crowd Video Understanding

- intro: CVPR 2016
- intro: It aims at learning generic spatio-temporal features from crowd videos, especially for long-term temporal learning
- project page: http://www.ee.cuhk.edu.hk/~jshao/SCNN.html
- paper: http://www.ee.cuhk.edu.hk/~jshao/papers_jshao/jshao_cvpr16_scnn.pdf
- github: https://github.com/amandajshao/Slicing-CNN
Rethinking Spatiotemporal Feature Learning For Video Understanding
https://arxiv.org/abs/1712.04851
Hierarchical Video Understanding
https://arxiv.org/abs/1809.03316
Challenges
THUMOS Challenge 2014
- homepage: http://crcv.ucf.edu/THUMOS14/home.html
- download: http://crcv.ucf.edu/THUMOS14/download.html
THUMOS Challenge 2015
- homepage: http://www.thumos.info/
- download: http://www.thumos.info/download.html
ActivityNet Challenge 2016

- homepage: http://activity-net.org/challenges/2016/
