Acceleration and Model Compression
Papers
High-Performance Neural Networks for Visual Object Classification
- intro: “reduced network parameters by randomly removing connections before training”
- arxiv: http://arxiv.org/abs/1102.0183
Predicting Parameters in Deep Learning
- intro: “decomposed the weighting matrix into two low-rank matrices”
- arxiv: http://arxiv.org/abs/1306.0543
Neurons vs Weights Pruning in Artificial Neural Networks
Exploiting Linear Structure Within Convolutional Networks for Efficient Evaluation
- intro: “presented a series of low-rank decomposition designs for convolutional kernels. singular value decomposition was adopted for the matrix factorization”
- paper: http://papers.nips.cc/paper/5544-exploiting-linear-structure-within-convolutional-networks-for-efficient-evaluation.pdf
cuDNN: Efficient Primitives for Deep Learning
- arxiv: https://arxiv.org/abs/1410.0759
- download: https://developer.nvidia.com/cudnn
Efficient and accurate approximations of nonlinear convolutional networks
- intro: “considered the subsequent nonlinear units while learning the low-rank decomposition”
- arxiv: http://arxiv.org/abs/1411.4229
Convolutional Neural Networks at Constrained Time Cost
Flattened Convolutional Neural Networks for Feedforward Acceleration
- intro: ICLR 2015
- arxiv: http://arxiv.org/abs/1412.5474
- github: https://github.com/jhjin/flattened-cnn
Compressing Deep Convolutional Networks using Vector Quantization
- intro: “this paper showed that vector quantization had a clear advantage over matrix factorization methods in compressing fully-connected layers.”
- arxiv: http://arxiv.org/abs/1412.6115
Speeding-up Convolutional Neural Networks Using Fine-tuned CP-Decomposition
- intro: “a low-rank CPdecomposition was adopted to transform a convolutional layer into multiple layers of lower complexity”
- arxiv: http://arxiv.org/abs/1412.6553
Deep Fried Convnets
- intro: “fully-connected layers were replaced by a single “Fastfood” layer for end-to-end training with convolutional layers”
- arxiv: http://arxiv.org/abs/1412.7149
Fast Convolutional Nets With fbfft: A GPU Performance Evaluation
- intro: Facebook. ICLR 2015
- arxiv: http://arxiv.org/abs/1412.7580
- github: http://facebook.github.io/fbcunn/fbcunn/
Caffe con Troll: Shallow Ideas to Speed Up Deep Learning
- intro: a fully compatible end-to-end version of the popular framework Caffe with rebuilt internals
- arxiv: http://arxiv.org/abs/1504.04343
Compressing Neural Networks with the Hashing Trick

- intro: HashedNets. ICML 2015
- intro: “randomly grouped connection weights into hash buckets, and then fine-tuned network parameters with back-propagation”
- project page: http://www.cse.wustl.edu/~wenlinchen/project/HashedNets/index.html
- arxiv: http://arxiv.org/abs/1504.04788
- code: http://www.cse.wustl.edu/~wenlinchen/project/HashedNets/HashedNets.zip
PerforatedCNNs: Acceleration through Elimination of Redundant Convolutions
- intro: NIPS 2016
- arxiv: https://arxiv.org/abs/1504.08362
- github: https://github.com/mfigurnov/perforated-cnn-matconvnet
- github: https://github.com/mfigurnov/perforated-cnn-caffe
Accelerating Very Deep Convolutional Networks for Classification and Detection
- intro: “considered the subsequent nonlinear units while learning the low-rank decomposition”
- arxiv: http://arxiv.org/abs/1505.06798
Fast ConvNets Using Group-wise Brain Damage
- intro: “applied group-wise pruning to the convolutional tensor to decompose it into the multiplications of thinned dense matrices”
- arxiv: http://arxiv.org/abs/1506.02515
Learning both Weights and Connections for Efficient Neural Networks
Data-free parameter pruning for Deep Neural Networks
- intro: “proposed to remove redundant neurons instead of network connections”
- arxiv: http://arxiv.org/abs/1507.06149
Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
- intro: ICLR 2016 Best Paper
- intro: “reduced the size of AlexNet by 35x from 240MB to 6.9MB, the size of VGG16 by 49x from 552MB to 11.3MB, with no loss of accuracy”
- arxiv: http://arxiv.org/abs/1510.00149
- video: http://videolectures.net/iclr2016_han_deep_compression/
Structured Transforms for Small-Footprint Deep Learning
- intro: NIPS 2015
- arxiv: https://arxiv.org/abs/1510.01722
- paper: https://papers.nips.cc/paper/5869-structured-transforms-for-small-footprint-deep-learning
ZNN - A Fast and Scalable Algorithm for Training 3D Convolutional Networks on Multi-Core and Many-Core Shared Memory Machines
Reducing the Training Time of Neural Networks by Partitioning
Convolutional neural networks with low-rank regularization
CNNdroid: Open Source Library for GPU-Accelerated Execution of Trained Deep Convolutional Neural Networks on Android
- arxiv: https://arxiv.org/abs/1511.07376
- paper: http://dl.acm.org/authorize.cfm?key=N14731
- slides: http://sharif.edu/~matin/pub/2016_mm_slides.pdf
- github: https://github.com/ENCP/CNNdroid
EIE: Efficient Inference Engine on Compressed Deep Neural Network
- intro: ISCA 2016
- arxiv: http://arxiv.org/abs/1602.01528
- slides: http://on-demand.gputechconf.com/gtc/2016/presentation/s6561-song-han-deep-compression.pdf
- slides: http://web.stanford.edu/class/ee380/Abstracts/160106-slides.pdf
Convolutional Tables Ensemble: classification in microseconds
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
- intro: DeepScale & UC Berkeley
- arxiv: http://arxiv.org/abs/1602.07360
- github: https://github.com/DeepScale/SqueezeNet
- homepage: http://songhan.github.io/SqueezeNet-Deep-Compression/
- github: https://github.com/songhan/SqueezeNet-Deep-Compression
- note: https://www.evernote.com/shard/s146/sh/108eea91-349b-48ba-b7eb-7ac8f548bee9/5171dc6b1088fba05a4e317f7f5d32a3
- github(Keras): https://github.com/DT42/squeezenet_demo
- github(Keras): https://github.com/rcmalli/keras-squeezenet
- github(PyTorch): https://github.com/gsp-27/pytorch_Squeezenet
SqueezeNet-Residual
- intro: Residual-SqueezeNet improves the top-1 accuracy of SqueezeNet by 2.9% on ImageNet without changing the model size(only 4.8MB).
- github: https://github.com/songhan/SqueezeNet-Residual
Lab41 Reading Group: SqueezeNet
Simplified_SqueezeNet
- intro: An improved version of SqueezeNet networks
- github(Caffe): https://github.com/NidabaSystems/Simplified_SqueezeNet
SqueezeNet Keras Dogs vs. Cats demo
Convolutional Neural Networks using Logarithmic Data Representation
DeepX: A Software Accelerator for Low-Power Deep Learning Inference on Mobile Devices
Hardware-oriented Approximation of Convolutional Neural Networks
- arxiv: http://arxiv.org/abs/1604.03168
- homepage: http://ristretto.lepsucd.com/
- github(“Ristretto: Caffe-based approximation of convolutional neural networks”): https://github.com/pmgysel/caffe
Deep Neural Networks Under Stress
- intro: ICIP 2016
- arxiv: http://arxiv.org/abs/1605.03498
- github: https://github.com/MicaelCarvalho/DNNsUnderStress
ASP Vision: Optically Computing the First Layer of Convolutional Neural Networks using Angle Sensitive Pixels
Deep Roots: Improving CNN Efficiency with Hierarchical Filter Groups
- intro: “for ResNet 50, our model has 40% fewer parameters, 45% fewer floating point operations, and is 31% (12%) faster on a CPU (GPU). For the deeper ResNet 200 our model has 25% fewer floating point operations and 44% fewer parameters, while maintaining state-of-the-art accuracy. For GoogLeNet, our model has 7% fewer parameters and is 21% (16%) faster on a CPU (GPU).”
- arxiv: https://arxiv.org/abs/1605.06489
Functional Hashing for Compressing Neural Networks
- intro: FunHashNN
- arxiv: http://arxiv.org/abs/1605.06560
Ristretto: Hardware-Oriented Approximation of Convolutional Neural Networks
YodaNN: An Ultra-Low Power Convolutional Neural Network Accelerator Based on Binary Weights
Learning Structured Sparsity in Deep Neural Networks
Design of Efficient Convolutional Layers using Single Intra-channel Convolution, Topological Subdivisioning and Spatial “Bottleneck” Structure
https://arxiv.org/abs/1608.04337
Dynamic Network Surgery for Efficient DNNs
- intro: NIPS 2016
- intro: compress the number of parameters in LeNet-5 and AlexNet by a factor of 108× and 17.7× respectively
- arxiv: http://arxiv.org/abs/1608.04493
- github(official. Caffe): https://github.com/yiwenguo/Dynamic-Network-Surgery
Scalable Compression of Deep Neural Networks
- intro: ACM Multimedia 2016
- arxiv: http://arxiv.org/abs/1608.07365
Pruning Filters for Efficient ConvNets
- intro: NIPS Workshop on Efficient Methods for Deep Neural Networks (EMDNN), 2016
- arxiv: http://arxiv.org/abs/1608.08710
Fixed-point Factorized Networks
Ultimate tensorization: compressing convolutional and FC layers alike
- intro: NIPS 2016 workshop: Learning with Tensors: Why Now and How?
- arxiv: https://arxiv.org/abs/1611.03214
- github: https://github.com/timgaripov/TensorNet-TF
Designing Energy-Efficient Convolutional Neural Networks using Energy-Aware Pruning
- intro: “the energy consumption of AlexNet and GoogLeNet are reduced by 3.7x and 1.6x, respectively, with less than 1% top-5 accuracy loss”
- arxiv: https://arxiv.org/abs/1611.05128
Net-Trim: A Layer-wise Convex Pruning of Deep Neural Networks
LCNN: Lookup-based Convolutional Neural Network
- intro: “Our fastest LCNN offers 37.6x speed up over AlexNet while maintaining 44.3% top-1 accuracy.”
- arxiv: https://arxiv.org/abs/1611.06473
Deep Tensor Convolution on Multicores
- intro: present the first practical CPU implementation of tensor convolution optimized for deep networks of small kernels
- arxiv: https://arxiv.org/abs/1611.06565
Training Sparse Neural Networks
FINN: A Framework for Fast, Scalable Binarized Neural Network Inference
- intro: Xilinx Research Labs & Norwegian University of Science and Technology & University of Sydney
- intro: 25th International Symposium on Field-Programmable Gate Arrays
- keywords: FPGA
- paper: http://www.idi.ntnu.no/~yamanu/2017-fpga-finn-preprint.pdf
- arxiv: https://arxiv.org/abs/1612.07119
- github: https://github.com/Xilinx/BNN-PYNQ
Deep Learning with INT8 Optimization on Xilinx Devices
- intro: “Xilinx’s integrated DSP architecture can achieve 1.75X solution-level performance at INT8 deep learning operations than other FPGA DSP architectures”
- paper: https://www.xilinx.com/support/documentation/white_papers/wp486-deep-learning-int8.pdf
Parameter Compression of Recurrent Neural Networks and Degredation of Short-term Memory
An OpenCL(TM) Deep Learning Accelerator on Arria 10
- intro: FPGA 2017
- arxiv: https://arxiv.org/abs/1701.03534
The Incredible Shrinking Neural Network: New Perspectives on Learning Representations Through The Lens of Pruning
- intro: CMU & Universitat Paderborn]
- arxiv: https://arxiv.org/abs/1701.04465
DL-gleaning: An Approach For Improving Inference Speed And Accuracy
- intro: Electronics Telecommunications Research Institute (ETRI)
- paper: https://openreview.net/pdf?id=Hynn8SHOx
Energy Saving Additive Neural Network
- intro: Middle East Technical University & Bilkent University
- arxiv: https://arxiv.org/abs/1702.02676
Soft Weight-Sharing for Neural Network Compression
- intro: ICLR 2017. University of Amsterdam
- arxiv: https://arxiv.org/abs/1702.04008
- github: https://github.com/KarenUllrich/Tutorial-SoftWeightSharingForNNCompression
A Compact DNN: Approaching GoogLeNet-Level Accuracy of Classification and Domain Adaptation
- intro: CVPR 2017
- arxiv: https://arxiv.org/abs/1703.04071
Deep Convolutional Neural Network Inference with Floating-point Weights and Fixed-point Activations
- intro: ARM Research
- arxiv: https://arxiv.org/abs/1703.03073
DyVEDeep: Dynamic Variable Effort Deep Neural Networks
https://arxiv.org/abs/1704.01137
Bayesian Compression for Deep Learning
https://arxiv.org/abs/1705.08665
A Kernel Redundancy Removing Policy for Convolutional Neural Network
https://arxiv.org/abs/1705.10748
Gated XNOR Networks: Deep Neural Networks with Ternary Weights and Activations under a Unified Discretization Framework
- keywords: discrete state transition (DST)
- arxiv: https://arxiv.org/abs/1705.09283
SEP-Nets: Small and Effective Pattern Networks
- intro: The University of Iowa & Snap Research
- arxiv: https://arxiv.org/abs/1706.03912
MEC: Memory-efficient Convolution for Deep Neural Network
- intro: ICML 2017
- arxiv: https://arxiv.org/abs/1706.06873
Data-Driven Sparse Structure Selection for Deep Neural Networks
https://arxiv.org/abs/1707.01213
An End-to-End Compression Framework Based on Convolutional Neural Networks
https://arxiv.org/abs/1708.00838
Domain-adaptive deep network compression
- intro: ICCV 2017
- arxiv: https://arxiv.org/abs/1709.01041
- github: https://github.com/mmasana/DALR
Binary-decomposed DCNN for accelerating computation and compressing model without retraining
https://arxiv.org/abs/1709.04731
Improving Efficiency in Convolutional Neural Network with Multilinear Filters
https://arxiv.org/abs/1709.09902
A Survey of Model Compression and Acceleration for Deep Neural Networks
- intro: IEEE Signal Processing Magazine. IBM Thoms J. Watson Research Center & Tsinghua University & Huazhong University of Science and Technology
- arxiv: https://arxiv.org/abs/1710.09282
Compression-aware Training of Deep Networks
- intro: NIPS 2017
- arxiv: https://arxiv.org/abs/1711.02638
Training Simplification and Model Simplification for Deep Learning: A Minimal Effort Back Propagation Method
https://arxiv.org/abs/1711.06528
Reducing Deep Network Complexity with Fourier Transform Methods
- intro: Harvard University
- arxiv: https://arxiv.org/abs/1801.01451
- github: https://github.com/andrew-jeremy/Reducing-Deep-Network-Complexity-with-Fourier-Transform-Methods
EffNet: An Efficient Structure for Convolutional Neural Networks
- intro: Aptiv & University of Wupperta
- arxiv: https://arxiv.org/abs/1801.06434
Universal Deep Neural Network Compression
https://arxiv.org/abs/1802.02271
Paraphrasing Complex Network: Network Compression via Factor Transfer
https://arxiv.org/abs/1802.04977
Compressing Neural Networks using the Variational Information Bottleneck
- intro: Tsinghua University & ShanghaiTech University & Microsoft Research
- arxiv: https://arxiv.org/abs/1802.10399
Adversarial Network Compression
https://arxiv.org/abs/1803.10750
Expanding a robot’s life: Low power object recognition via FPGA-based DCNN deployment
- intro: MOCAST 2018
- arxiv: https://arxiv.org/abs/1804.00512
Accelerating CNN inference on FPGAs: A Survey
- intro: [Institut Pascal]
- arxiv: https://arxiv.org/abs/1806.01683
Doubly Nested Network for Resource-Efficient Inference
https://arxiv.org/abs/1806.07568
Smallify: Learning Network Size while Training
- intro: MIT
- arxiv: https://arxiv.org/abs/1806.03723
Synetgy: Algorithm-hardware Co-design for ConvNet Accelerators on Embedded FPGAs
- intro: 27th International Symposium on Field-Programmable Gate Arrays, February 2019
- arxiv: https://arxiv.org/abs/1811.08634
Cascaded Projection: End-to-End Network Compression and Acceleration
https://arxiv.org/abs/1903.04988
FALCON: Fast and Lightweight Convolution for Compressing and Accelerating CNN
https://arxiv.org/abs/1909.11321
Compressing Deep Neural Network
Deep k-Means: Re-Training and Parameter Sharing with Harder Cluster Assignments for Compressing Deep Convolutions
- intro: ICML 2018
- arxiv: https://arxiv.org/abs/1806.09228
- github: https://github.com/Sandbox3aster/Deep-K-Means-pytorch
Optimize Deep Convolutional Neural Network with Ternarized Weights and High Accuracy
- intro: University of Central Florida & Tencent AI lab, Seattle
- arxiv: https://arxiv.org/abs/1807.07948
Blended Coarse Gradient Descent for Full Quantization of Deep Neural Networks
https://arxiv.org/abs/1808.05240
ChannelNets: Compact and Efficient Convolutional Neural Networks via Channel-Wise Convolutions
- intro: NIPS 2018
- arxiv: https://arxiv.org/abs/1809.01330
A Framework for Fast and Efficient Neural Network Compression
https://arxiv.org/abs/1811.12781
ComDefend: An Efficient Image Compression Model to Defend Adversarial Examples
https://arxiv.org/abs/1811.12673
Pruning
ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression
- intro: ICCV 2017. Nanjing University & Shanghai Jiao Tong University
- arxiv: https://arxiv.org/abs/1707.06342
- github(Caffe): https://github.com/Roll920/ThiNet
Neuron Pruning for Compressing Deep Networks using Maxout Architectures
- intro: GCPR 2017
- arxiv: https://arxiv.org/abs/1707.06838
Fine-Pruning: Joint Fine-Tuning and Compression of a Convolutional Network with Bayesian Optimization
- intro: BMVC 2017 oral. Simon Fraser University
- arxiv: https://arxiv.org/abs/1707.09102
Prune the Convolutional Neural Networks with Sparse Shrink
https://arxiv.org/abs/1708.02439
NISP: Pruning Networks using Neuron Importance Score Propagation
- intro: University of Maryland & IBM T. J. Watson Research
- arxiv: https://arxiv.org/abs/1711.05908
Automated Pruning for Deep Neural Network Compression
https://arxiv.org/abs/1712.01721
Learning to Prune Filters in Convolutional Neural Networks
https://arxiv.org/abs/1801.07365
Recovering from Random Pruning: On the Plasticity of Deep Convolutional Neural Networks
- intro: WACV 2018
- arxiv: https://arxiv.org/abs/1801.10447
A novel channel pruning method for deep neural network compression
https://arxiv.org/abs/1805.11394
PCAS: Pruning Channels with Attention Statistics
- intro: Oki Electric Industry Co., Ltd
- arxiv: https://arxiv.org/abs/1806.05382
Soft Filter Pruning for Accelerating Deep Convolutional Neural Networks
- intro: IJCAI 2018
- arxiv: https://arxiv.org/abs/1808.06866
- github: https://github.com/he-y/soft-filter-pruning
Progressive Deep Neural Networks Acceleration via Soft Filter Pruning
https://arxiv.org/abs/1808.07471
Pruning neural networks: is it time to nip it in the bud?
https://arxiv.org/abs/1810.04622
Rethinking the Value of Network Pruning
https://arxiv.org/abs/1810.05270
Dynamic Channel Pruning: Feature Boosting and Suppression
https://arxiv.org/abs/1810.05331
Interpretable Convolutional Filter Pruning
https://arxiv.org/abs/1810.07322
Progressive Weight Pruning of Deep Neural Networks using ADMM
https://arxiv.org/abs/1810.07378
Pruning Deep Neural Networks using Partial Least Squares
- arxiv: https://arxiv.org/abs/1810.07610
- github: https://github.com/arturjordao/PruningNeuralNetworks
Hybrid Pruning: Thinner Sparse Networks for Fast Inference on Edge Devices
https://arxiv.org/abs/1811.00482
Discrimination-aware Channel Pruning for Deep Neural Networks
- intro: NIPS 2018
- arxiv: https://arxiv.org/abs/1810.11809
Stability Based Filter Pruning for Accelerating Deep CNNs
- intro: WACV 2019
- arxiv: https://arxiv.org/abs/1811.08321
Structured Pruning for Efficient ConvNets via Incremental Regularization
- intro: NIPS 2018 workshop on “Compact Deep Neural Network Representation with Industrial Applications”
- arxiv: https://arxiv.org/abs/1811.08390
Graph-Adaptive Pruning for Efficient Inference of Convolutional Neural Networks
https://arxiv.org/abs/1811.08589
A Layer Decomposition-Recomposition Framework for Neuron Pruning towards Accurate Lightweight Networks
- intro: AAAI 2019 as oral
- intro: Hikvision Research Institute
- arxiv: https://arxiv.org/abs/1812.06611
Quantized Guided Pruning for Efficient Hardware Implementations of Convolutional Neural Networks
https://arxiv.org/abs/1812.11337
Towards Compact ConvNets via Structure-Sparsity Regularized Filter Pruning
https://arxiv.org/abs/1901.07827
Partition Pruning: Parallelization-Aware Pruning for Deep Neural Networks
https://arxiv.org/abs/1901.11391
Pruning from Scratch
- intro: Tsinghua University & Ant Financial & Huawei Noah’s Ark Lab
- arxiv: https://arxiv.org/abs/1909.12579
Global Sparse Momentum SGD for Pruning Very Deep Neural Networks
- intro: NeurIPS 2019
- arxiv: https://arxiv.org/abs/1909.12778
FNNP: Fast Neural Network Pruning Using Adaptive Batch Normalization
- openreview: https://openreview.et/forum?id=rJeUPlrYvr
- paper: https://openreview.net/pdf?id=rJeUPlrYvr
- github: https://github.com/anonymous47823493/FNNP
Pruning Filter in Filter
- intro: NeurIPS 2020
- intro: Harbin Institute of Technology & Tencent Youtu Lab
- arxiv: https://arxiv.org/abs/2009.14410
Low-Precision Networks
Accelerating Deep Convolutional Networks using low-precision and sparsity
- intro: Intel Labs
- arxiv: https://arxiv.org/abs/1610.00324
Deep Learning with Low Precision by Half-wave Gaussian Quantization
- intro: HWGQ-Net
- arxiv: https://arxiv.org/abs/1702.00953
Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights
- intro: ICLR 2017
- arxiv: https://arxiv.org/abs/1702.03044
- openreview: https://openreview.net/forum?id=HyQJ-mclg¬eId=HyQJ-mclg
ShiftCNN: Generalized Low-Precision Architecture for Inference of Convolutional Neural Networks
Extremely Low Bit Neural Network: Squeeze the Last Bit Out with ADMM
- intro: Alibaba Group
- keywords: alternating direction method of multipliers (ADMM)
- arxiv: https://arxiv.org/abs/1707.09870
Learning Accurate Low-Bit Deep Neural Networks with Stochastic Quantization
- intro: BMVC 2017 Oral
- arxiv: https://arxiv.org/abs/1708.01001
Compressing Low Precision Deep Neural Networks Using Sparsity-Induced Regularization in Ternary Networks
- intro: ICONIP 2017
- arxiv: https://arxiv.org/abs/1709.06262
Learning Low Precision Deep Neural Networks through Regularization
https://arxiv.org/abs/1809.00095
Discovering Low-Precision Networks Close to Full-Precision Networks for Efficient Embedded Inference
https://arxiv.org/abs/1809.04191
SQuantizer: Simultaneous Learning for Both Sparse and Low-precision Neural Networks
- intro: Movidius, AIPG, Intel
- arxiv: https://arxiv.org/abs/1812.08301
Quantized Neural Networks
Quantized Convolutional Neural Networks for Mobile Devices
- intro: Q-CNN
- intro: “Extensive experiments on the ILSVRC-12 benchmark demonstrate 4 ∼ 6× speed-up and 15 ∼ 20× compression with merely one percentage loss of classification accuracy”
- arxiv: http://arxiv.org/abs/1512.06473
- github: https://github.com/jiaxiang-wu/quantized-cnn
Training Quantized Nets: A Deeper Understanding
- intro: University of Maryland & Cornell University
- arxiv: https://arxiv.org/abs/1706.02379
Balanced Quantization: An Effective and Efficient Approach to Quantized Neural Networks
- intro: the top-5 error rate of 4-bit quantized GoogLeNet model is 12.7%
- arxiv: https://arxiv.org/abs/1706.07145
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
- intro: CVPR 2018. Google
- arxiv: https://arxiv.org/abs/1712.05877
Deep Neural Network Compression with Single and Multiple Level Quantization
- intro: AAAI 2018. Shanghai Jiao Tong University & University of Chinese Academy of Sciences
- arxiv: https://arxiv.org/abs/1803.03289
Quantizing deep convolutional networks for efficient inference: A whitepaper
- intro: Google
- arxiv: https://arxiv.org/abs/1806.08342
CascadeCNN: Pushing the Performance Limits of Quantisation in Convolutional Neural Networks
- intro: 28th International Conference on Field Programmable Logic & Applications (FPL), 2018
- arxiv: https://arxiv.org/abs/1807.05053
Bridging the Accuracy Gap for 2-bit Quantized Neural Networks (QNN)
- intro: IBM Research AI
- arxiv: https://arxiv.org/abs/1807.06964
Joint Training of Low-Precision Neural Network with Quantization Interval Parameters
https://arxiv.org/abs/1808.05779
Differentiable Fine-grained Quantization for Deep Neural Network Compression
https://arxiv.org/abs/1810.10351
HAQ: Hardware-Aware Automated Quantization
https://arxiv.org/abs/1811.08886
DNQ: Dynamic Network Quantization
- intro: Shanghai Jiao Tong University & Qualcomm AI Research
- arxiv: https://arxiv.org/abs/1812.02375
Trained Rank Pruning for Efficient Deep Neural Networks
- intro: Shanghai Jiao Tong University & Qualcomm AI Research & Duke University
- arxiv: https://arxiv.org/abs/1812.02402
Training Quantized Network with Auxiliary Gradient Module
- intro: The University of Adelaide & Australian Centre for Robotic Vision & South China University of Technology
- arxiv: https://arxiv.org/abs/1903.11236
FLightNNs: Lightweight Quantized Deep Neural Networks for Fast and Accurate Inference
- intro: Carnegie Mellon University
- intro: https://arxiv.org/abs/1904.02835
And the Bit Goes Down: Revisiting the Quantization of Neural Networks
- intro: Facebook AI Research & Univ Rennes
- arxiv: https://arxiv.org/abs/1907.05686
Differentiable Soft Quantization: Bridging Full-Precision and Low-Bit Neural Networks
- intro: ICCV 2019
- arxiv: https://arxiv.org/abs/1908.05033
Bit Efficient Quantization for Deep Neural Networks
- intro: NeurIPS workshop 2019
- arxiv: https://arxiv.org/abs/1910.04877
Quantization Networks
- intro: CVPR 2019
- arxiv: https://arxiv.org/abs/1911.09464
Adaptive Loss-aware Quantization for Multi-bit Networks
https://arxiv.org/abs/1912.08883
Distribution Adaptive INT8 Quantization for Training CNNs
- intro: AAAI 2021
- intro: Machine Intelligence Technology Lab, Alibaba Group
- arxiv: https://arxiv.org/abs/2102.04782
Distance-aware Quantization
- intro: ICCV 2021
- arxiv: https://arxiv.org/abs/2108.06983
Binary Convolutional Neural Networks / Binarized Neural Networks
BinaryNet: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1
Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1
https://arxiv.org/abs/1602.02830
Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations
https://arxiv.org/abs/1609.07061
XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks
- arxiv: http://arxiv.org/abs/1603.05279
- github(Torch): https://github.com/mrastegari/XNOR-Net
XNOR-Net++: Improved Binary Neural Networks
- intro: BMVC 2019
- arxiv: https://arxiv.org/abs/1909.13863
DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients
https://arxiv.org/abs/1606.06160
A 7.663-TOPS 8.2-W Energy-efficient FPGA Accelerator for Binary Convolutional Neural Networks
Espresso: Efficient Forward Propagation for BCNNs
BMXNet: An Open-Source Binary Neural Network Implementation Based on MXNet
- keywords: Binary Neural Networks (BNNs)
- arxiv: https://arxiv.org/abs/1705.09864
- github: https://github.com/hpi-xnor
ShiftCNN: Generalized Low-Precision Architecture for Inference of Convolutional Neural Networks
https://arxiv.org/abs/1706.02393
Binarized Convolutional Neural Networks with Separable Filters for Efficient Hardware Acceleration
- intro: Embedded Vision Workshop (CVPRW). UC San Diego & UC Los Angeles & Cornell University
- arxiv: https://arxiv.org/abs/1707.04693
Embedded Binarized Neural Networks
https://arxiv.org/abs/1709.02260
Compact Hash Code Learning with Binary Deep Neural Network
- intro: Singapore University of Technology and Design
- arxiv: https://arxiv.org/abs/1712.02956
Build a Compact Binary Neural Network through Bit-level Sensitivity and Data Pruning
https://arxiv.org/abs/1802.00904
From Hashing to CNNs: Training BinaryWeight Networks via Hashing
https://arxiv.org/abs/1802.02733
Energy Efficient Hadamard Neural Networks
- keywords: Binary Weight and Hadamard-transformed Image Network (BWHIN), Binary Weight Network (BWN), Hadamard-transformed Image Network (HIN)
- arxiv: https://arxiv.org/abs/1805.05421
Binary Ensemble Neural Network: More Bits per Network or More Networks per Bit?
https://arxiv.org/abs/1806.07550
Bi-Real Net: Enhancing the Performance of 1-bit CNNs With Improved Representational Capability and Advanced Training Algorithm
- intro: ECCV 2018
- arxiv: https://arxiv.org/abs/1808.00278
Training Compact Neural Networks with Binary Weights and Low Precision Activations
https://arxiv.org/abs/1808.02631
Training wide residual networks for deployment using a single bit for each weight
- intro: ICLR 2018
- arxiv: https://arxiv.org/abs/1802.08530
- github(official, PyTorch): https://github.com/szagoruyko/binary-wide-resnet
Composite Binary Decomposition Networks
https://arxiv.org/abs/1811.06668
Training Competitive Binary Neural Networks from Scratch
- intro: University of Potsdam
- intro: BMXNet v2: An Open-Source Binary Neural Network Implementation Based on MXNet
- arxiv: https://arxiv.org/abs/1812.01965
- github: https://github.com/hpi-xnor/BMXNet-v2
Regularizing Activation Distribution for Training Binarized Deep Networks
- intro: Carnegie Mellon University
- arxiv: https://arxiv.org/abs/1904.02823
GBCNs: Genetic Binary Convolutional Networks for Enhancing the Performance of 1-bit DCNNs
- intro: AAAI 2020
- arxiv: https://arxiv.org/abs/1911.11634
Training Binary Neural Networks with Real-to-Binary Convolutions
- intro: ICLR 2020
- intro: Samsung AI Research Center, Cambridge, UK & The University of Nottingham
- arxiv: https://arxiv.org/abs/2003.11535
- github: https://github.com/brais-martinez/real2binary
Accelerating / Fast Algorithms
Fast Algorithms for Convolutional Neural Networks
- intro: “2.6x as fast as Caffe when comparing CPU implementations”
- keywords: Winograd’s minimal filtering algorithms
- arxiv: http://arxiv.org/abs/1509.09308
- github: https://github.com/andravin/wincnn
- slides: http://homes.cs.washington.edu/~cdel/presentations/Fast_Algorithms_for_Convolutional_Neural_Networks_Slides_reading_group_uw_delmundo_slides.pdf
- discussion: https://github.com/soumith/convnet-benchmarks/issues/59#issuecomment-150111895
- reddit: https://www.reddit.com/r/MachineLearning/comments/3nocg5/fast_algorithms_for_convolutional_neural_networks/?
Speeding up Convolutional Neural Networks By Exploiting the Sparsity of Rectifier Units
- intro: Hong Kong Baptist University
- arxiv: https://arxiv.org/abs/1704.07724
NullHop: A Flexible Convolutional Neural Network Accelerator Based on Sparse Representations of Feature Maps
https://arxiv.org/abs/1706.01406
Channel Pruning for Accelerating Very Deep Neural Networks
- intro: ICCV 2017. Megvii Inc
- arxiv: https://arxiv.org/abs/1707.06168
- github: https://github.com/yihui-he/channel-pruning
DeepRebirth: Accelerating Deep Neural Network Execution on Mobile Devices
https://arxiv.org/abs/1708.04728
Learning Efficient Convolutional Networks through Network Slimming
- intro: ICCV 2017
- arxiv: https://arxiv.org/abs/1708.06519
SparCE: Sparsity aware General Purpose Core Extensions to Accelerate Deep Neural Networks
https://arxiv.org/abs/1711.06315
Accelerating Convolutional Neural Networks for Continuous Mobile Vision via Cache Reuse
- keywords: CNNCache
- arxiv: https://arxiv.org/abs/1712.01670
Learning a Wavelet-like Auto-Encoder to Accelerate Deep Neural Networks
- intro: AAAI 2018
- arxiv: https://arxiv.org/abs/1712.07493
SBNet: Sparse Blocks Network for Fast Inference
- intro: Uber
- project page: https://eng.uber.com/sbnet/
- arxiv: https://arxiv.org/abs/1801.02108
- github: https://github.com/uber/sbnet
Accelerating deep neural networks with tensor decompositions
- blog: https://jacobgil.github.io/deeplearning/tensor-decompositions-deep-learning
- github: https://github.com/jacobgil/pytorch-tensor-decompositions
A Survey on Acceleration of Deep Convolutional Neural Networks
https://arxiv.org/abs/1802.00939
Recurrent Residual Module for Fast Inference in Videos
- intro: CVPR 2018
- arxiv: https://arxiv.org/abs/1802.09723
Co-Design of Deep Neural Nets and Neural Net Accelerators for Embedded Vision Applications
- intro: UC Berkeley & Samsung Research
- arxiv: https://arxiv.org/abs/1804.10642
Towards Efficient Convolutional Neural Network for Domain-Specific Applications on FPGA
https://arxiv.org/abs/1809.03318
Accelerating Deep Neural Networks with Spatial Bottleneck Modules
https://arxiv.org/abs/1809.02601
FPGA Implementation of Convolutional Neural Networks with Fixed-Point Calculations
https://arxiv.org/abs/1808.09945
Extended Bit-Plane Compression for Convolutional Neural Network Accelerators
https://arxiv.org/abs/1810.03979
DAC: Data-free Automatic Acceleration of Convolutional Networks
- intro: WACV 2019
- intro: Qualcomm AI Research & Lehigh University
- arxiv: https://arxiv.org/abs/1812.08374
Learning Instance-wise Sparsity for Accelerating Deep Models
- intro: IJCAI 2019
- arxiv: https://arxiv.org/abs/1907.11840
Code Optimization
Production Deep Learning with NVIDIA GPU Inference Engine
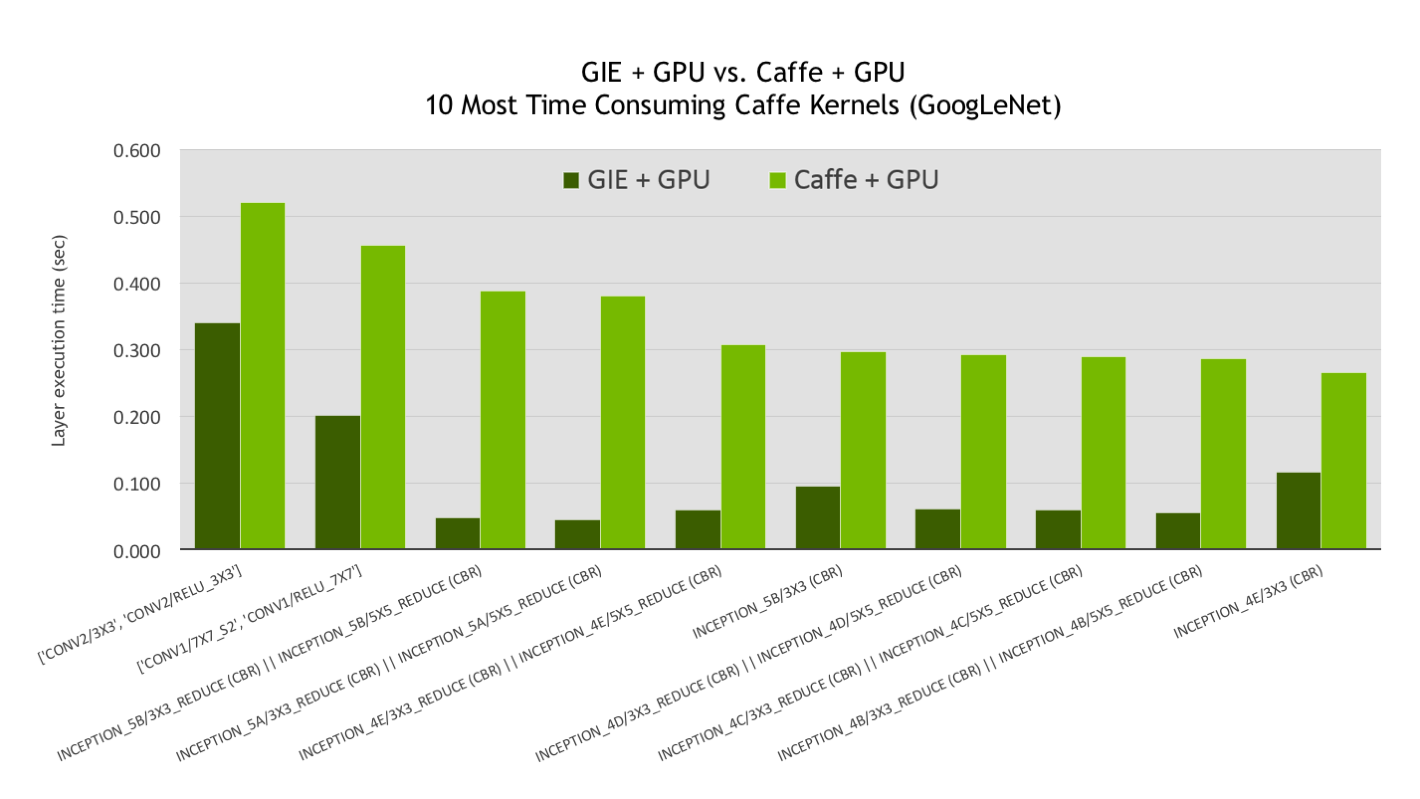
- intro: convolution, bias, and ReLU layers are fused to form a single layer: CBR
- blog: https://devblogs.nvidia.com/parallelforall/production-deep-learning-nvidia-gpu-inference-engine/
speed improvement by merging batch normalization and scale #5
- github issue: https://github.com/sanghoon/pva-faster-rcnn/issues/5
Add a tool to merge ‘Conv-BN-Scale’ into a single ‘Conv’ layer.
https://github.com/sanghoon/pva-faster-rcnn/commit/39570aab8c6513f0e76e5ab5dba8dfbf63e9c68c/
Low-memory GEMM-based convolution algorithms for deep neural networks
https://arxiv.org/abs/1709.03395
Projects
Accelerate Convolutional Neural Networks
- intro: “This tool aims to accelerate the test-time computation and decrease number of parameters of deep CNNs.”
- github: https://github.com/dmlc/mxnet/tree/master/tools/accnn
OptNet
OptNet - reducing memory usage in torch neural networks
NNPACK: Acceleration package for neural networks on multi-core CPUs
- github: https://github.com/Maratyszcza/NNPACK
- comments(Yann LeCun): https://www.facebook.com/yann.lecun/posts/10153459577707143
Deep Compression on AlexNet
Tiny Darknet
CACU: Calculate deep convolution neurAl network on Cell Unit
keras_compressor: Model Compression CLI Tool for Keras
- blog: https://nico-opendata.jp/ja/casestudy/model_compression/index.html
- github: https://github.com/nico-opendata/keras_compressor
Blogs
Neural Networks Are Impressively Good At Compression
https://probablydance.com/2016/04/30/neural-networks-are-impressively-good-at-compression/
“Mobile friendly” deep convolutional neural networks
- part 1: https://medium.com/@sidd_reddy/mobile-friendly-deep-convolutional-neural-networks-part-1-331120ad40f9#.uy64ladvz
- part 2: https://medium.com/@sidd_reddy/mobile-friendly-deep-convolutional-neural-networks-part-2-making-deep-nets-shallow-701b2fbd3ca9#.u58fkuak3
Lab41 Reading Group: Deep Compression
Accelerating Machine Learning

Compressing and regularizing deep neural networks
https://www.oreilly.com/ideas/compressing-and-regularizing-deep-neural-networks
How fast is my model?
http://machinethink.net/blog/how-fast-is-my-model/
Talks / Videos
Deep compression and EIE: Deep learning model compression, design space exploration and hardware acceleration
Deep Compression, DSD Training and EIE: Deep Neural Network Model Compression, Regularization and Hardware Acceleration
http://research.microsoft.com/apps/video/default.aspx?id=266664
Tailoring Convolutional Neural Networks for Low-Cost, Low-Power Implementation
- intro: tutorial at the May 2015 Embedded Vision Summit
- youtube: https://www.youtube.com/watch?v=xACJBACStaU
Resources
awesome-model-compression-and-acceleration
https://github.com/sun254/awesome-model-compression-and-acceleration
Embedded-Neural-Network
- intro: collection of works aiming at reducing model sizes or the ASIC/FPGA accelerator for machine learning
- github: https://github.com/ZhishengWang/Embedded-Neural-Network
